
Faculty
I am a tenure-track faculty at the CISPA Helmholtz Center for Information Security, where I have led research in trustworthy AI systems since 2022. I received my PhD from Ruhr University Bochum in 2021 with a dissertation on adversarially robust speech and speaker recognition, supported by the DFG Cluster of Excellence CASA. After my PhD, I was a postdoctoral researcher at Ruhr University Bochum and CISPA, and a visiting researcher at the University of California, Berkeley, and the University of Chicago.
In my research group Dormant Neurons we work on the security of AI systems, spanning LLMs and agentic pipelines, speech and audio models, code-generating models, preventing the misuse of generative AI, and the human factors involved in AI-driven threats. We also critically examine how AI security research itself is conducted. Our research covers both attacks and defenses, with the goal of building AI that is secure, safe, and reliable such that trust emerges from understanding and transparency rather than blind reliance.
Building secure, safe, and reliable AI people can understand and trust.
As large language models are deployed in real-world pipelines they introduce novel attack surfaces. Our work addresses these from multiple angles: designing defenses against prompt injection attacks (Prompt Obfuscation), analyse hidden intentions in LLMs (Unknown Unknowns), and how LLMs can both be exploited for and applied to code analysis and deobfuscation (Code Deobfuscation, CodeLMSec).
AI-generated content, whether images or audio, is increasingly indistinguishable from authentic media, enabling misinformation, fraud, and manipulation at scale. Our research works toward preventing this misuse: developing detectors for synthetic audio (WaveFake) and GAN-generated images (frequency analysis), studying how these detectors hold up under adversarial pressure in realistic conditions (Adversarial Robustness of Image Detectors), and examining how content labeling and warnings affect human trust and detection behavior (AI Image Labeling).
Many AI security threats succeed not through technical exploits but by targeting or involving human judgment. Our research examines these human dimensions from several angles: how people detect AI-generated media across countries (Human Detection Study), how content labeling affects trust and detection behavior (Labeling AI-Generated Images), and how everyday voice interfaces can be accidentally triggered by ambient audio (Accidental Triggers).
Beyond individual attacks and defenses, some of our work questions how security research itself is conducted. One thread systematically examines nine methodological pitfalls in LLM security research, including data leakage, model ambiguity, prompt sensitivity, context truncation, and the surrogate fallacy, finding that every reviewed paper contains at least one (Chasing Shadows). Another draws on a community-scale red-teaming competition to analyze what current LLM security benchmarks can and cannot tell us (SaTML CTF).
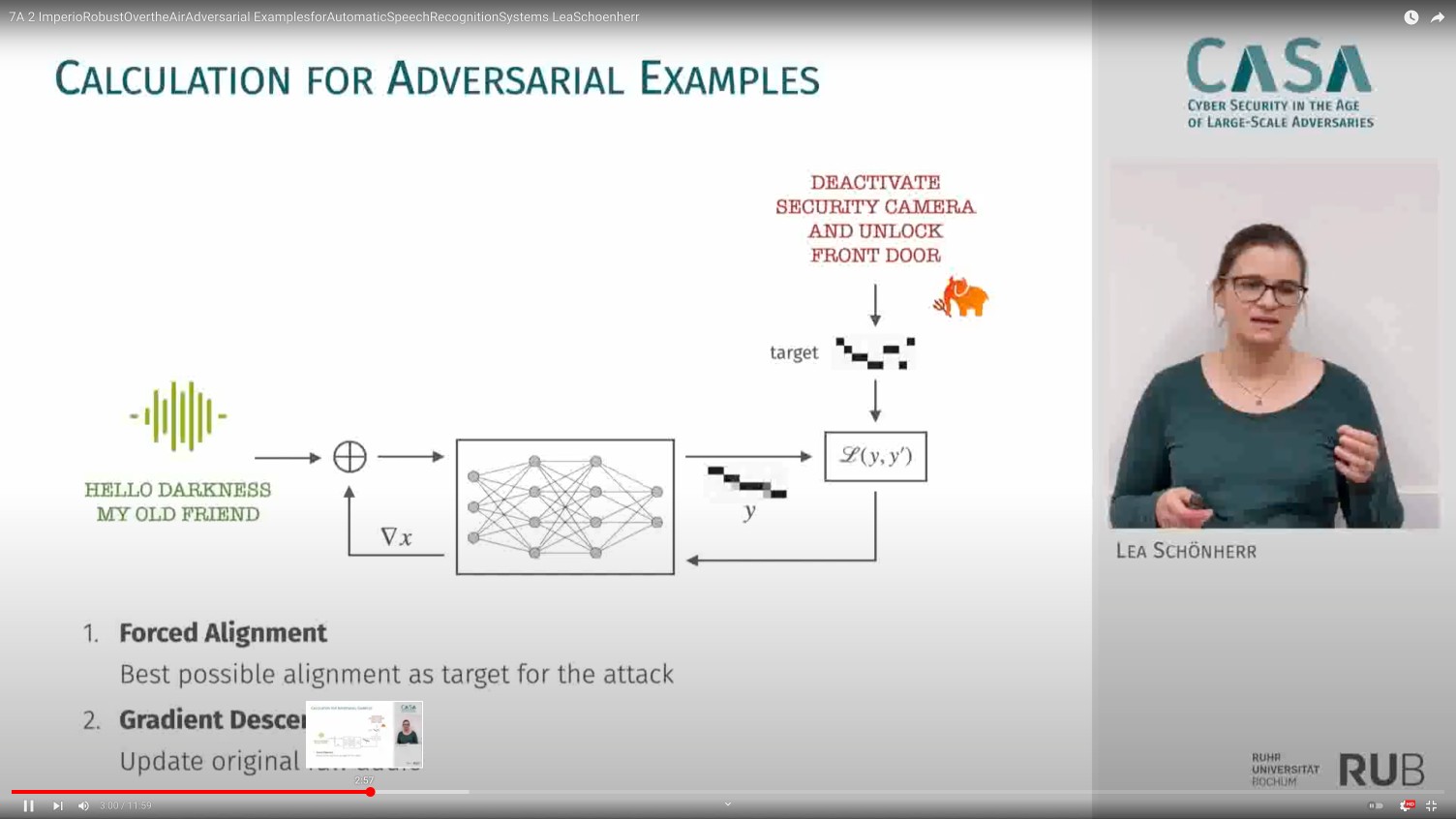
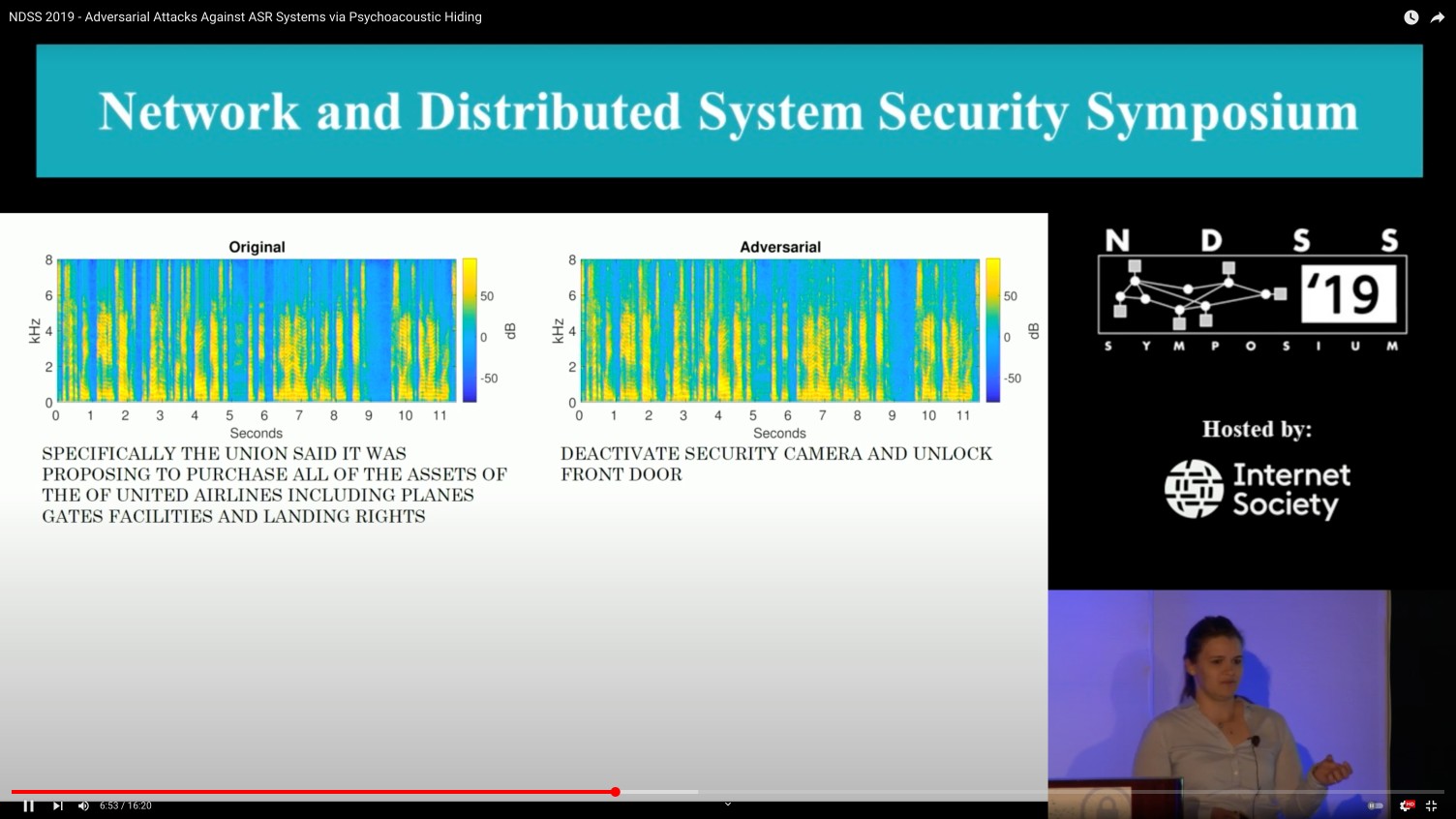
Security research requires grounding in both offense and defense. On the offensive side, our work studies adversarial examples on speech recognition via psychoacoustic hiding (Psychoacoustic Hiding) and robust over-the-air perturbations (Imperio), adversarial examples on deepfake detectors (Adversarial Robustness), and eliciting security vulnerabilities from code language models (CodeLMSec). On the defensive side: perceptually constrained defenses for audio adversarial examples (Dompteur) and prompt obfuscation against injection attacks (Prompt Obfuscation).
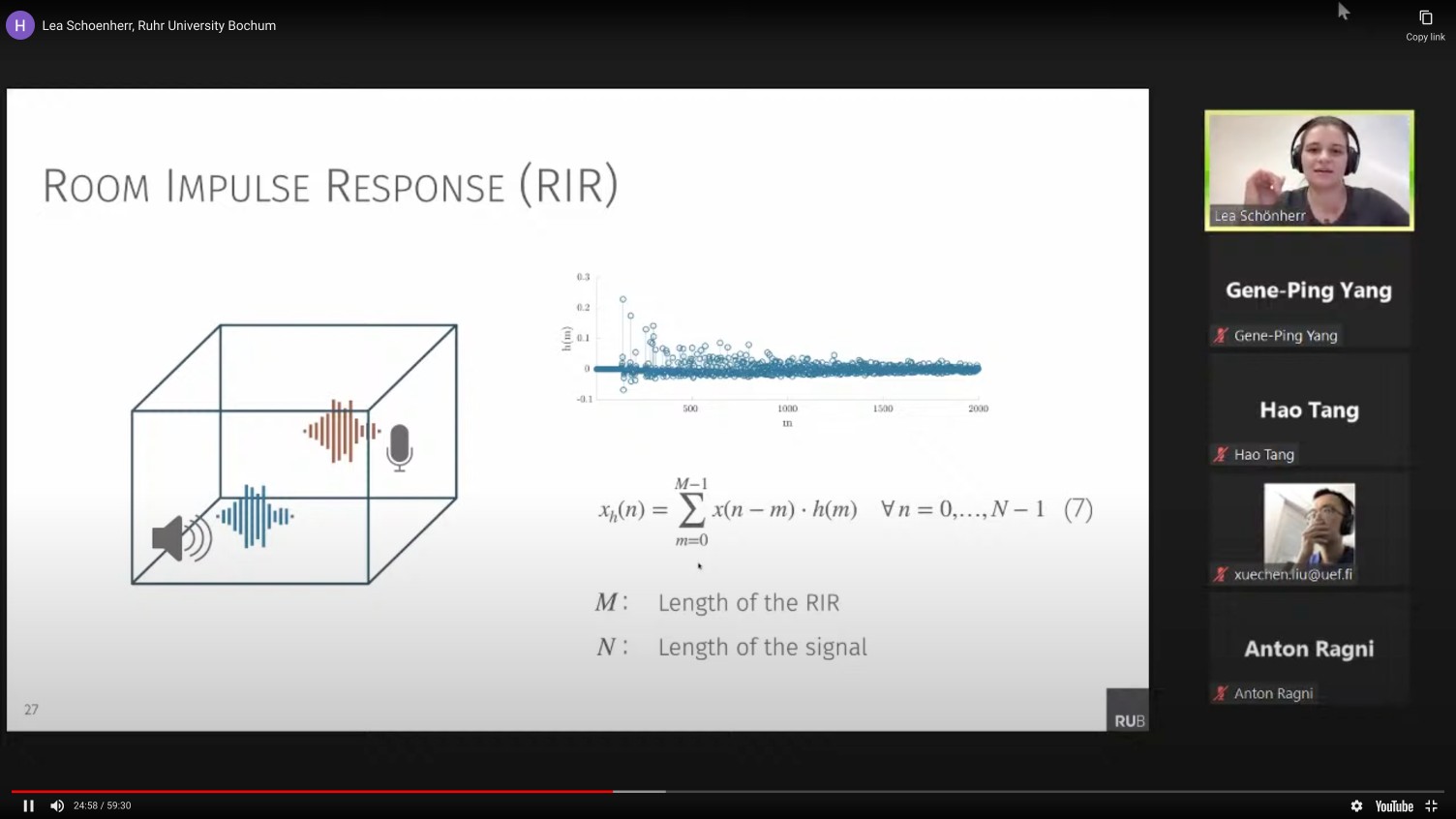
Voice interfaces are a recurrent focus of our research. Early work established core attack methods: adversarial examples via psychoacoustic hiding (Psychoacoustic Hiding), robust over-the-air perturbations (Imperio), and clean-label poisoning of speech recognition models (VENOMAVE). On the defensive side: perceptually constrained defenses (Dompteur) and privacy-preserving wake-word designs. More recently, this work extends to audio deepfake detection (WaveFake) and evaluating the fairness, safety, and security of audio language models (Audio LM Evaluation).






Selected highlights
More coverage
My teaching focuses on secure and trustworthy machine learning, adversarial AI, and the risks and chances of generative models on graduate and undergraduate levels. I aim to equip students with both strong technical foundations and a critical understanding of real-world security risks in modern AI systems, as well as research practice. I regularly teach lectures, seminars, and at international summer schools. My courses combine theoretical lectures with hands-on exercises and projects which are continuously curated to reflect current research trends and practical applications.
Machine learning systems are increasingly deployed in high-stakes and security-sensitive environments, ranging from generative AI assistants and code generation systems to autonomous decision-making pipelines. As these systems become more capable, ensuring their robustness, security, fairness, and accountability becomes essential.
This lecture introduces the foundations of trustworthy machine learning. We examine how modern ML systems can fail, how they can be attacked, and how principled defenses can be designed. The course emphasizes a security-oriented perspective on machine learning, integrating robustness, privacy, and interpretability.
Core Topics
 Saarland University
Saarland University
As artificial intelligence systems evolve from pattern recognition tools to autonomous decision-making systems, they increasingly function as agents rather than passive models. These agentic systems are capable of planning, acting, and adapting to dynamic environments. While such capabilities significantly enhance their utility, they also introduce fundamental questions regarding reliability, safety, and alignment with human objectives.
This seminar examines the conceptual and technical foundations required to build trustworthy agentic AI systems. Rather than emphasizing scale or efficiency, the course focuses on principled system design, evaluation, and oversight mechanisms.
Core Questions
Saarland University
Generative machine learning systems such as large language models, image generators, and speech synthesis tools are increasingly integrated into everyday applications. While these systems demonstrate impressive capabilities, they also raise important questions about reliability, security, fairness, and societal impact.
This bachelor-level seminar introduces students to the foundations of trustworthy generative machine learning. We examine how generative models work, where they can fail, and how they may be misused. The focus lies on understanding risks and developing principled approaches to make these systems more robust, transparent, and aligned with human values.
Topics Covered
Saarland University
Saarland University
Top Reviewer Recognition
Chairs & Organization
Program Committees
In addition, I have served as a reviewer in several workshops, such as the ACM Workshop on Artificial Intelligence and Security (AISec) and the Workshop on New Frontiers in Adversarial Machine Learning (AdvML-Frontiers).
 Lea Schönherr
Lea Schönherr